
Are you ready to dive deep into the secrets of Google Search Console Crawl Reports? In this article, we will unravel the mysteries and uncover the hidden gems of this powerful tool. Whether you’re a seasoned SEO expert or just starting out, understanding the crawl reports can give you valuable insights into how Google interacts with your website.
With Google Search Console Crawl Reports, you can discover which pages on your site Google has crawled, and whether any issues were encountered during the process. This information is crucial for improving your website’s visibility and performance in search results.
Throughout this article, we will explore the various sections of the Crawl Reports, including the Crawl Errors report, the Crawl Stats report, and the robots.txt tester. We will provide you with practical tips and strategies to maximize the potential of these reports and optimize your website for better search engine rankings.
So, strap on your scuba gear and get ready to plunge into the depths of the Google Search Console Crawl Reports. Let’s uncover the hidden treasures that will help you achieve online success.
Understanding crawl reports in Google Search Console
Google Search Console provides webmasters with valuable information about how their websites are crawled and indexed by Google. The crawl reports, in particular, offer insights into the crawling process and any issues that may have been encountered.
The Crawl Reports section is divided into three main categories: Crawl Errors, Crawl Stats, and robots.txt Tester. Each of these categories serves a specific purpose in helping you understand and optimize your website’s crawlability.
Let’s start by exploring the Crawl Errors report.
Crawl Errors report
The Crawl Errors report provides a detailed overview of any errors encountered by Google while crawling your website. These errors can include server errors, DNS errors, and URL errors. By identifying and fixing these errors, you can ensure that Google can properly crawl and index your site.
One of the most common crawl errors is the “404 Not Found” error, which occurs when a page cannot be found on your website. This can happen if a page has been deleted or if the URL structure has changed. By fixing these errors and redirecting users to the correct pages, you can improve your website’s user experience and search engine rankings.
Another type of crawl error is the “500 Internal Server Error,” which indicates a server-side issue that prevented Google from accessing your website. This error can be caused by misconfigurations or server overload. By resolving these errors, you can ensure that your website is accessible to both users and search engines.
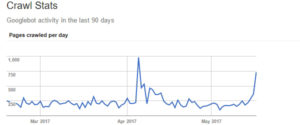
Crawl Stats report
The Crawl Stats report provides valuable data about how Google crawls your website over time. It includes information such as the total number of pages crawled, the average time spent downloading a page, and the kilobytes downloaded per day.
By analyzing this data, you can gain insights into how Google perceives the speed and performance of your website. If you notice a significant increase in the time it takes for Google to download your pages, it may indicate performance issues that need to be addressed. Improving your website’s speed can not only enhance the user experience but also boost your search engine rankings.
Robots.txt Tester
The robots.txt file is a text file that tells search engine crawlers which parts of your website they are allowed to crawl and index. The Robots.txt Tester in Google Search Console allows you to test and validate your robots.txt file to ensure that it is properly configured.
By using the Robots.txt Tester, you can check if any pages or directories are being blocked from being crawled by search engines. It is important to ensure that your robots.txt file is correctly set up to avoid unintentionally blocking important pages or sections of your website. This can negatively impact your website’s visibility in search results.
In the next section, we will delve deeper into how to interpret crawl errors and take steps to fix them for improved website performance.
Importance of crawl reports for SEO
Crawl reports play a vital role in optimizing your website for search engines. By understanding the data provided in these reports, you can identify and address any issues that may be hindering your website’s visibility and performance in search results.
One of the key benefits of crawl reports is that they help you identify crawl errors, which are issues that prevent search engines from properly crawling and indexing your website. By fixing these errors, you can ensure that your website is fully accessible to search engine crawlers, allowing them to index and rank your pages accurately.
Crawl reports also provide valuable insights into the performance of your website. The Crawl Stats report, for example, gives you data on how Google crawls your pages, including the number of pages crawled, the time spent downloading pages, and the total kilobytes downloaded.
This information can help you identify any performance bottlenecks and take steps to improve your website’s speed and efficiency. Furthermore, crawl reports can help you optimize your website’s content.
By analyzing the crawl data, you can identify which pages are being crawled frequently and which pages are being ignored. This information can guide your content creation strategy, allowing you to focus on creating high-quality content for the pages that matter most to search engines.
In the next section, we will explore how to interpret crawl errors and take actionable steps to fix them for improved website performance.
Key metrics and data in crawl reports
Crawl reports provide a wealth of valuable metrics and data that can help you understand how Google interacts with your website. By analyzing this data, you can gain insights into the crawling process, identify any issues, and take steps to optimize your website for better search engine rankings.
One of the key metrics in crawl reports is the number of pages crawled. This metric tells you how many pages on your website were visited by Google’s crawlers during a specific time period. By monitoring this metric over time, you can identify any sudden drops or spikes in crawl activity and investigate the underlying reasons.
Another important metric is the time spent downloading a page. This metric indicates how long it takes for Google to download a page from your website. If you notice an increase in this metric, it may suggest that your website’s performance is slowing down, potentially affecting user experience and search engine rankings.
The total kilobytes downloaded per day is yet another critical metric in crawl reports. This metric shows how much data Google downloads from your website on a daily basis. By monitoring this data, you can identify any anomalies that may indicate excessive bandwidth usage or potential server issues.
Other data in crawl reports includes the number of crawl requests made by Google, the number of kilobytes downloaded per crawl request, and the average response time of your server. By analyzing these metrics, you can gain a comprehensive understanding of how Google interacts with your website and take appropriate actions to optimize its performance.
In the next section, we will delve deeper into how to interpret crawl errors and take actionable steps to fix them for improved website performance.
Interpreting crawl errors and warnings
Crawl errors are issues that prevent search engine crawlers, such as Googlebot, from properly accessing and indexing your website. These errors can have a significant impact on your website’s visibility and search engine rankings. By understanding and fixing these errors, you can ensure that your website is fully accessible to search engines.
One common crawl error is the “404 Not Found” error. This error occurs when a page on your website cannot be found. It can happen if a page has been deleted or if the URL structure has changed.
When Google encounters a 404 error, it assumes that the page no longer exists and may remove it from its index. To fix this error, you should redirect the URL to a relevant page or create a custom 404 page that provides useful information to users.
Another common crawl error is the “500 Internal Server Error.” This error indicates a server-side issue that prevented Google from accessing your website. It can be caused by misconfigurations, server overload, or other technical problems.
To fix this error, you should investigate the server logs, identify the underlying issue, and take appropriate actions to resolve it. Additionally, crawl warnings are notifications that alert you to potential issues that may affect how search engines crawl and index your website.
These warnings do not necessarily prevent your website from being crawled, but they indicate areas that may need attention for better search engine optimization. One common crawl warning is the “Blocked by robots.txt” warning.
This warning occurs when a page or directory on your website is blocked from being crawled by search engines. To fix this warning, you should review your robots.txt file and ensure that it allows search engines to access the pages you want to be indexed.
In the next section, we will explore practical strategies for fixing crawl errors and warnings to improve your website’s performance.
Analyzing crawl data for content optimization
Crawl data provides valuable insights into how search engines perceive and interact with your website’s content. By analyzing this data, you can identify content optimization opportunities and improve your website’s search engine rankings.
One of the key aspects of content optimization is understanding which pages on your website are being crawled frequently and which pages are being ignored by search engines. By analyzing the crawl data, you can identify pages that receive a high number of crawls and ensure that they are optimized for relevant keywords and user intent.
For pages that receive fewer crawls, it may indicate that search engines do not consider them as important or relevant. In such cases, you can optimize these pages by improving their content, adding internal links, and promoting them through other channels to increase their visibility and crawlability.
Analyzing crawl data can also help you identify duplicate content issues. If multiple pages on your website have similar or identical content, search engines may have difficulty determining which page to rank.
By identifying and consolidating duplicate content, you can ensure that search engines focus on the most relevant and authoritative page, improving your website’s search engine rankings.
Additionally, analyzing crawl data can help you identify and fix broken links within your website. Broken links not only negatively impact user experience but also affect how search engines crawl and index your website.
By regularly monitoring crawl data and fixing broken links, you can ensure that your website is fully accessible to both users and search engine crawlers. By leveraging crawl data for content optimization, you can improve your website’s visibility, user experience, and search engine rankings.
The insights gained from analyzing crawl data can guide your content creation strategy, ensuring that your website’s content aligns with search engine algorithms and user intent.